

By Raouf B., Expert DevOps SQUAD
Kubernetes is one of the most widely used open-source container orchestration platform. It helps to automate the deployment, scaling, self-healing, service discovery, and management of applications using containers.

Stateless applications are a perfect use case to be fully managed by Kubernetes in contrast to Stateful ones which require more complex operations requiring manual actions. The Kubernetes operators extend Kubernetes control plane and API by adding application-specific operational knowledge, making it easier to automate repetitive maintenance operations such as upgrades, backups, recovery from failure, etc.
In other word: Think of a Kubernetes Operator as an SRE in a Software :)
Kubernetes Operators, a must-have for all Stateful apps ?
Kubernetes automates the Lifecyle of a stateless application, such as a web server. Without state, all pods are interchangeable. Other applications have state, they often have particulars of configuration, startup, component interdependency, persistence storage, etc. These Stateful applications have their own notion of “cluster”. In this article, we will focus on running an Apache Kafka cluster on top of Kubernetes using an open-source Operator.
Kubernetes does not and should not know about Apache Kafka! The operator teaches Kubernetes how to manage it by adding an endpoint to the API called a custom resource definition (CRD).
All the logic is implemented by taking the action based on the state of the CRD instance or simply custom resource (CR).
Making an Operator means creating a CRD and providing a program that runs in a loop watching CRs of that kind. What the Operator does in response to changes in the CR is specific to the application the Operator manages. For Apache Kafka, the actions an Operator performs can include for instance : cluster expansion or scaling, version upgrades, disk extension, rebalance, topics creation, etc.
You can find out a lot of operators in the Operatorhub.io , which is designed as a public registry for finding services backed by Kubernetes Operators, such as: Couchebase, MongoDB, Prometheus, Grafana, Redis, Kafka, etc.
Why use Strimzi with Apache Kafka?
Announced on feb 25th 2018, Strimzi is an Open-Source Project under Apache Licence 2.0 and maintained by RedHat and IMB. It focuses on running Apache Kafka on Kubernetes and provides all the container images for Apache Kafka. Strimzi simplifies operators work for deploying, managing and configuring Kafka clusters, topics and users.
Strimzi Cluster Operator Pattern
The Cluster Operator is used to deploy a Kafka cluster and other Kafka components by watching Kafka CRs. Configuring a performing Kafka cluster is not an easy task, by letting the administrator defining the desired state in YAML, the operator will make sure that what is declared is reconciled with the actual state in Kubernetes.
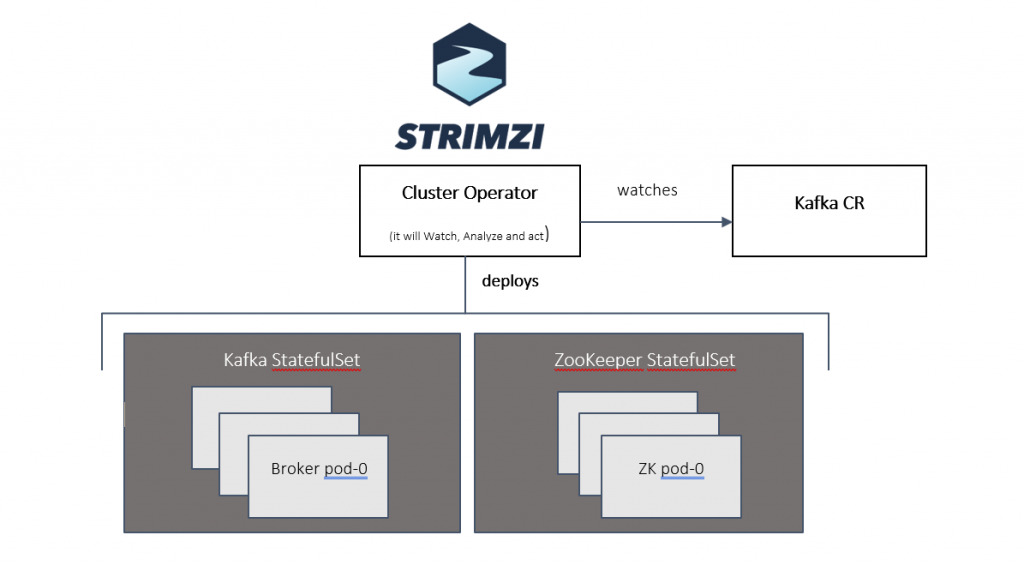
For a rolling update of Apache Kafka cluster, the operator logic will execute these subsequent steps in this order:
- Watch Kafka CR changes
- Apply new config to Kafka StatefulSet spec
- Starting from pod 0, delete the pod and allow the StatefulSet to recreate it
- Kafka pod will generate a new broker config
- Kafka is started
- Wait until health checks are good
- Repeat from step 3 for the next pod
Conclusion
Thanks to Operators, now we can easily deploy and manage complex applications on Kubernetes. For enterprise usage, the Operators can make informed decisions and free engineers from repetitive operational tasks to get focus on innovation. For local development or testing, engineers can deploy a variety of tools and components like Databases, event buses, monitoring stacks using a couple of command lines. However, we should not forget that having an Operator working, the engineers must code it first. So, think about your repetitive manual tasks, roll up your sleeves and build your own operator !

